
基因體醫學生技研發生物資訊核心
GMBD Core Services 教育訓練課程
|
主辦單位: |
國家衛生研究院 |
| 國立清華大學 生物資訊中心 | |
| 國立交通大學 生物資訊中心 | |
| 國立成功大學 生物資訊中心 | |
| 基因體醫學國家型科技計畫 |
![]() 簡介:
簡介:
基因體醫學生技研發生物資訊核心 (GMBD Bioinformatics Core) 是台灣生物資訊組織(Taiwan Bioinformatics Institute,簡稱TBI) 所設置的核心設施,目標在於結合生物資訊社群的力量,提供快速便捷且完善的生物資訊服務,健全台灣的生物資訊基礎建設。目前核心設施由基因體醫學國家型計畫資助,成員包括:國家衛生研究院-協調中心、統計遺傳、比較基因體學及交互蛋白質體;國立清華大學-計算蛋白質體;國立交通大學-結構生物資訊學;國立成功大學-應用基因體醫學。核心設施把所有成員提供的服務分類整理,透過單一的網站,讓研究人員可以使用這四個機構的所有生物資訊服務。
GMBD Bioinformatics Core 入口網站,包含20幾種各式生物資訊分析工具及加值資料庫,為了讓國內生命科學之研究者熟悉並運用這些分析工具,特舉辦 GMBD Core Services推廣教育課程,課程內容包括Comparative Genomics and Interactomes、 Applied Medical Genomics、Computational Proteomics 、Structural Bioinformatics等四個領域的資料庫、分析工具原理介紹及實際操作,希望藉此讓使用者了解各項分析工具的功能和應用,有助於生物資訊研究工作的推展。
![]() 課程內容:
課程內容:
時間:96年 5月14日到 5月15日 (週一、週二) 共二天不同主題之課程
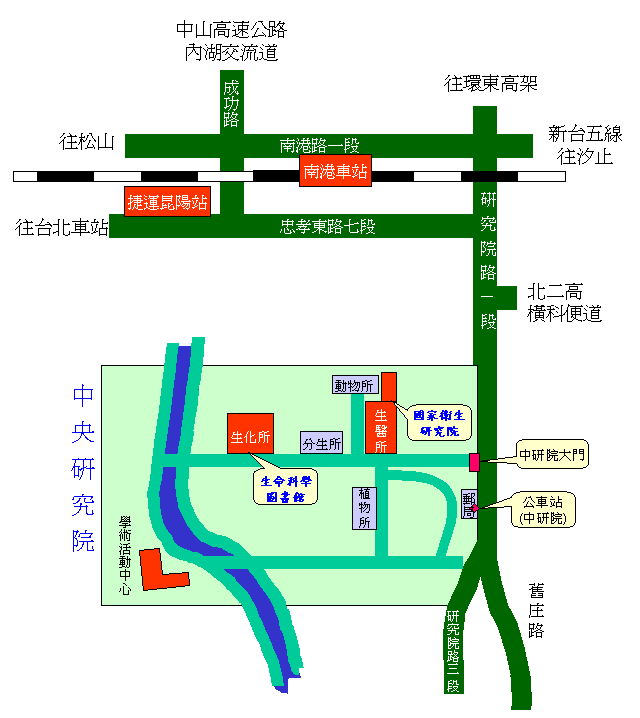
地點:中研院生圖電腦教室
北市研究院路二段 128 號 [地圖]上課人數:分為 14日、15日兩天不同主題,每日各 50人
報名費:免費
{kind=link}
![]() 議程:
議程:
| 第一天場次 96年 5月14日 星期一 | |
| 08:30-09:00 | 報 到 |
| 主題一:Comparative Genomics and Interactomes | |
| 09:00-09:30 |
Array-CGH Data Analysis |
| 09:40-10:30 | POWER (Phylogenetic WEb Repeater) 親緣演化分析樹及程式操作 主講人:林介華 女士 國家衛生研究院 生物統計與生物資訊研究組 |
| 簡介:本系統為整合性自動化可反覆執行之序列親緣關係分析工具,結合 ClustalW 和 Phylip,簡化繁瑣的序列格式處理過程及流暢地銜接多種操作程序,並以導引式互動介面協助使用者完成分析;另外也保留了各分析階段中參數微調的功能,並自動記錄操作過程的參數設定,以便使用者回溯其工作流程,再行調整。另外,針對樹形圖的輸出方式,與樹形分支排列調整等功能設計程式,以符合客製化 (customize) 的理想。 | |
| 10:40-11:30 | PDA (Primer Design Assistant) 核酸引子設計工具的應用及程式操作 主講人:林仲彥 博士 中央研究院 資訊科學研究所 |
| 簡介:有鑑於一般常用的PCR核酸引子設計程式所套用的模型往往過於簡化,而無法找到最合適的引子配對,本系統以熱力學原理為基礎,設計考量因子涵蓋了大部份已知會影響PCR 實驗的可能原因,以及為了因應High throughput 大規模實驗,PDA容許一次單筆或多筆核酸序列資料同時進行線上最佳化分析,均一化所需批次進行的PCR 反應條件,有效地提高實驗的效能比與成功率。 | |
| 11:40-12:30 | DPI (Database of Protein Interactomes) 蛋白質體交互作用脈絡網資料庫及使用介面操作 主講人:林仲彥 博士 中央研究院 資訊科學研究所 |
| 簡介:透過hp-DPI之視覺整合與預測系統平台,協助使用者以人性化的圖像網路介面,探究H.pylori中的蛋白質交互作用。其中整合的註解資料來源包括Genbank、GO、KEGG,並以實驗數據為基礎,透過關連式分析進行功能預測,特別是應用在藥物試驗的驗證和大規模篩檢,更能有效縮小目標蛋白質的搜尋範圍。 | |
| 12:30-13:30 | 休息 |
| 主題二:Applied Medical Genomics | |
| 13:30-14:20 | SNP value-added database 主講人: 孫孝芳 副教授 國立成功大學 分子醫學研究所 |
| 簡介:SNP 是最常見的基因變異,在遺傳學及遺傳疾病的研究上扮演重要的角色。此加值型的資料庫內容包括兩個主要的SNP資料庫(dbSNP及HGVbase) 的資料外,也加上專屬華人族群的SNP資料庫,將這三者結合,形成了一個整合性的SNP資料庫。因此在使用時可將資料作一整體性、跨種族的呈現。 | |
| 14:30-15:40 | RepeatMasker server 主講人: 孫孝芳 副教授 國立成功大學 分子醫學研究所 |
| 簡介:RepeatMasker可將欲查詢的DNA序列中低複雜度的重覆性片段做篩選,如LINE、SINE、或是微衛星標竿等。並可將篩選出來的結果予以標記及加註解。使用者可以再將其輸出的結果帶到 BLAST 做更進一步的搜尋比對,因此可增加序列搜尋的正確性 | |
| 15:50-16:50 | TAG: Tumor Associated Gene 加值型資料庫 主講人:孫孝芳 副教授 國立成功大學 分子醫學研究所 |
| 簡介:致癌基因 / 抑癌基因 的變異跟癌症的形成有著密切的關係,增加對此兩種基因的分子遺傳特性瞭解,可以讓我們更加認識癌症的成因。TAG加值型資料庫收集了已知與癌症相關的基因及其蛋白質的資訊,並提供方便的查詢、分析及資料收集整合介面,讓使用者可以透過整合性的觀點來研究跟癌症相關的基因。 | |
| 第二天場次 96年 5月15日 星期二 | |
| 08:30-09:00 | 報到 |
| 主題一:Computational Proteomics | |
| 09:00-09:50 | Genome Profile DataBase (GPDB) 原理與實作 主講人: 呂平江 教授 國立清華大學 生命科學系/生物資訊與結構生物研究所 |
| 簡介:GPDB has been developed to provide and compare features of the fully sequenced organisms in a graphic and easy-reading way. We focus on these prokaryotes including bacteria and archaea. In this post-genome era, we try to grab the information derived from both nucleotide and protein sequence in a genome-wide scale. We provide some "Genome Profile", develop on-line graphic browsing interface and use hierarchical clustering method to compare and view the difference between these organisms. | |
| 10:00-10:30 | SARST: Structure Alignment by Ramachandran Search Tool之應用與實作 主講人: 呂平江 教授 國立清華大學 生命科學研究所 |
| 簡介:Searching similar protein structures of the specified protein in PDB | |
| 10:30-11:10 | KPST: KEGG pathway search tool 之應用與實作 主講人: 呂平江 教授 國立清華大學 生命科學研究所 |
| 簡介:Introduction to KEGG pathway and KEGG pathway search tool in NTHU (KPST) | |
| 11:20-12:30 | (Tm) Database 主講人: 呂平江 教授 國立清華大學 生命科學研究所 |
| 簡介:Introduction to melting temperature (Tm) database in NTHU and melting temperature prediction. | |
| 12:30-13:30 | 休息 |
| 主題二:Structural Bioinformatics | |
| 13:30-14:10 | CELLO-- 蛋白質 subcellular location 預測 主講人:游景盛 先生 國立交通大學 生物資訊研究所 |
| 簡介:蛋白質在生命體中的位置(subcellular location)與其生理功能有著密切的關係,如果知道某蛋白質的subcellular location,就能幫助分析該蛋白質的功能。利用支持向量機(SVM: Support Vector Machines),使用各種不同多樣特性的 n-peptide 組成份,並針對已知的幾個標準資料群作測試。這個方法可以延伸到其他的生物體,而且對於大規模high-throughput的蛋白質體和基因體資料分析相當有幫助,即為CELLO的功能。 | |
| 14:10-14:50 | (PS)2 Server-- 利用同源模擬 (homology modeling) 預測蛋白質結構 主講人:陳志杰 先生 國立交通大學 生物資訊研究所 |
| 簡介:(PS)2 是利用同源模擬 (homology modeling) 來預測蛋白質結構的工具,它可自動化的預測蛋白質三級結構。本課程將介紹同源模擬四個重要的步驟︰(1)資料庫搜尋及選擇模版(templates selection);(2) 多重序列排列(multiple sequence alignment);(3)結構模擬(model building);(4)結構合理性評估(model evaluation)。並配合(PS)2的實際操作,讓學員對蛋白質三級結構的預測有基本的了解。 | |
| 15:10-15:50 | GEMDOCK -- 分子嵌合預測工具 (molecular docking tool) 之操作與應用 主講人:陳彥甫 先生 國立交通大學 生物資訊研究所 |
| 簡介:配體嵌合預測(molecular docking)在藥物設計領域中是一個重要的技術。GEMDOCK (Generic Evolutionary Method for molecular DOCKing) 是以演化式方法為基的彈性配體嵌合 (flexible ligand docking) 程式。主要目的是計算一配基分子與目標蛋白質之活性區域結合後之結構與位置。此工具可應用於單一配基與蛋白質之結合預測與大規模之虛擬藥物篩選。GEMDOCK的功效在與國內外超過八實驗室合作中得到相當的印證,尤其是合作實驗室利用GEMDOCK發現登革熱病毒新的抑制劑(細胞實驗上)。本課程將介紹GEMDOCK之安裝與應用,提供對分子嵌合預測有需求的研究人員使用參考。 | |
| 15:50-16:30 | 3D-BLAST-- 蛋白質三級結構資料庫搜尋工具 主講人:董其樺 先生 國立交通大學 生物資訊研究所 |
| 簡介:後基因體時代中,功能性結構基因體學的研究日漸重要。基因體計畫中大部分的基因所轉譯之蛋白質,透過成熟的技術已經能快速解出其結晶結構,但卻尚無法立即明瞭其生物性功能為何。針對此議題,我們發展出一套快速蛋白質資料庫搜尋工具:3D-BLAST,用以搜尋新結晶蛋白質在資料庫中有哪些結構相似的同源蛋白質,同時可決定其功能性演化的分類。3D-BLAST 具備原 BLAST 的優點與特色,如快速、有效、與提供 E-value 的統計意義等,3D-BLAST可在2秒內,搜尋一萬個以上的蛋白質三級結構。本課程將介紹3D-BLAST之理論基礎與方法原理,並實地操作3D-BLAST所提供之網頁工具。 | |
![]() 報名方式及注意事項:
報名方式及注意事項:
-
一律線上報名,報名網頁請見 http://registry.nhri.org.tw/apply_form.asp。
96 年 5 月 06 日 或報名額滿即截止。由於座位有限,如報名人數過多,本院保留篩選學員之權利。 - 上課名單將於課程開始前三天公布於本網頁,同時以 E-mail 通知錄取學員,敬請務必提供正確的 E-mail ,謝謝!
- 本課程恕不供應午餐。
![]() 洽詢方式:
洽詢方式:
國家衛生研究院 生醫資源中心
電話:(037) 206166 轉 36164
傳真:(037) 586410
E-mail:service@tbi.org.tw
地址:350苗栗縣竹南鎮科研路35號