
腎臟病歷結構化應用系統建置
腎臟病歷結構化應用系統建置
隨著智慧醫療的普及,病歷結構化技術的應用日益受到關注。病歷結構化旨在將非結構化的醫療文本轉換為結構化數據,以實現有效的存儲、檢索和分析醫學資訊的目的。為了實現系統的核心功能,本核心許聞廉老師研究團隊採用以知識為本體的架構,結合深度學習中的雙向長短期記憶(BiLSTM)和條件隨機場演算法(CRF)作為系統核心設計概念,並以此辨識醫療報告中常見的命名實體。
在病歷結構化的過程中,首先運用預定義的規則來識別和標記病歷中的特定元素,例如症狀、診斷、疾病等。這些規則基於醫學知識和醫學文本的特徵,可以有效地捕捉到常見的醫學實體。接著,針對未被規則標記的文本內容,我們運用深度學習模型中的BiLSTM和CRF進行系統學習訓練和預測。該模型能夠捕捉醫學實體之間的關聯性和內在語意,並利用上下文資訊來推斷其正確的類別和屬性,進一步提高結構化的準確性和廣度。
除此之外,我們從UMLS (Unified Medical Language System)資料庫中擷取相關的醫學詞彙,包括疾病名稱,並整合為系統後端支援的知識圖譜。知識圖譜的建立是基於許聞廉教授團隊開發的InformapJ知識庫(Knowledge Base)管理平台。該平台為系統提供了堅實的開發基礎,讓生醫語意分析師能夠透過簡易的編輯介面有效地管理和組織醫學相關的知識和資訊,從而增強系統在醫學知識管理和分析方面的能力。
深度學習模型在識別實體方面雖然具有優越性能,但難免會出現例外情況。因此,系統策略導入基於語言學特徵的審查模組,對識別後的實體進行驗證。這些特徵包含詞彙上下文關係、語法結構、專有名詞規則等。透過將這些特徵應用於識別結果,令系統得以排除潛在的例外情況,提高識別結果的準確性和一致性。以腎臟病歷結構化系統評估模型效能,可針對病徵、病程以及基本進行有效辨識達九成以上的F1-score,具體表現呈現如表一。
本次開發的病歷結構化工具充分整合了規則蘊含的準確性以及統計模型的彈性優勢,進而提高病歷結構化的精度和召回率,透過提供如圖一的應用系統介面,系統可協助醫護人員處理單篇或多篇批次病歷文本資料,再以如圖二的視覺化結果頁面呈現,為醫療機構提供更準確、全面且易於管理的醫學資訊,從而促進臨床決策的準確性和效率。
表一、腎臟病歷結構化系統效能評估
|
|
Precision |
Recall |
F1-score |
support |
|
Title_section |
1.00 |
1.00 |
1.00 |
24,251 |
|
disease_location |
0.97 |
0.99 |
0.98 |
5,716 |
|
disease_name |
0.99 |
1.00 |
0.99 |
18,100 |
|
graft_kidney_size |
1.00 |
1.00 |
1.00 |
412 |
|
left_kidney_size |
1.00 |
1.00 |
1.00 |
18,565 |
|
renal_cyst_amount |
0.99 |
0.99 |
0.99 |
5,234 |
|
renal_cyst_location |
0.97 |
0.99 |
0.98 |
9,851 |
|
renal_cyst_mention |
0.99 |
1.00 |
0.99 |
11,286 |
|
renal_cyst_morph_progression |
0.99 |
1.00 |
0.99 |
1,408 |
|
renal_cyst_size |
0.98 |
1.00 |
0.99 |
5,565 |
|
right_kidney_size |
1.00 |
1.00 |
1.00 |
18,563 |
|
micro avg |
0.99 |
1.00 |
0.99 |
118,951 |
|
macro avg |
0.99 |
1.00 |
0.99 |
118,951 |
|
weighted avg |
0.99 |
1.00 |
0.99 |
118,951 |
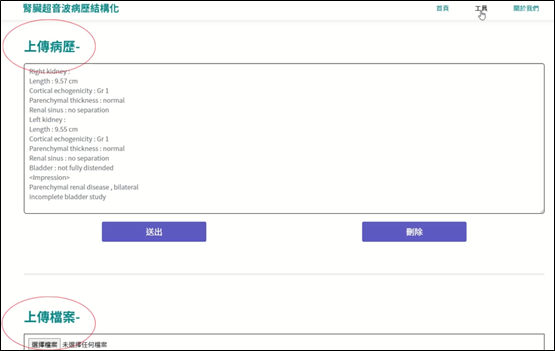 圖一、腎臟病歷應用系統病歷上傳介面
圖一、腎臟病歷應用系統病歷上傳介面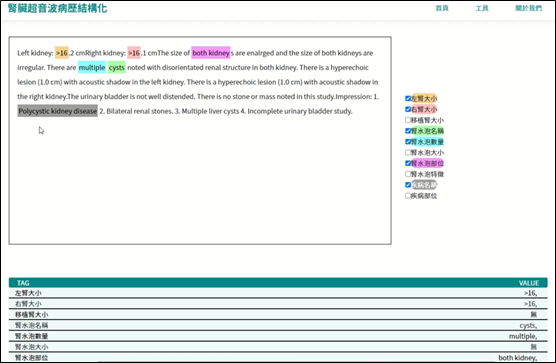 圖二、應用系統結果呈現示意圖
圖二、應用系統結果呈現示意圖