
高通量資料中的批次效應受注意
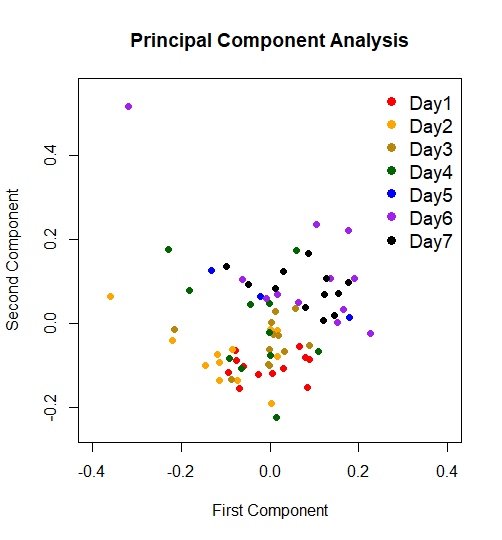
批次效應示意圖。以日期為實驗批號註記之不同批次gene expression profiling (nanoString 技術)實驗,在PCA分析(principle component analysis, 主成份分析)結果中形成群聚現象(clustering),顯示基因表現之差異主要來源明顯與實驗批次有關。
多體學(multi-omics)時代利用各種先進技術產生的高通量(high-throughput)數據,正持續以驚人的速度累積於各式公開資料庫(如TCGA、ICGC等)中。利用這些基因組資料庫進行不同層次的資料整理、探索(exploration)、統計分析及生物解讀,以產生或支援生物學假設,已成為一種例行的研究模式。TBI生物資訊核心團隊於上述相關領域的客製化服務或使用者提出之合作需求與日俱增,反應了科學研究重視真實性及再現性的本質。
依據我們的服務或合作經驗及文獻閱讀,發現往往有忽略或低估了實驗的批次效應(batch effect)對分析結果之再現性產生的影響。大型研究計畫(如TCGA)衍生的公開資料庫,在某些層次已經考慮並修正批次效應的影響,但不同計畫所衍生之公開資料庫間的批次效應目前仍是存在而待解決。另外,使用者自己產生的高通量數據中的批次效應,也常被習慣性地忽略。批次效應誤導或影響結果的闡釋發表在高影響力的期刊的例子不少,更應為吾人所警惕。我們在高通量資料分析的教育訓練課程中,已將高通量數據中批次效應的介紹及處理列為例行性教材,歡迎同好一起了解、討論。