
辨識一組癌症生物標記集合的組合最佳化演算法
本核心交通大學生物資訊所何信瑩所長所帶領的研究團隊,目前發展了一個生物標記(biomarker)辨識與分析平台,包含核心技術為辨識一組癌症生物標記集合(cancer signature)的組合最佳化演算法,本文將對此演算法目前的研究成果與提供服務做一簡介。
辨識一組癌症生物標記集合的演算法
由於各種基因體定序方法的成功發展,以致於累積了大量的核酸資料庫。這些資料庫啟發了計算領域的專家學者發展更有效與精準的分析方法來探尋各種癌症疾病的生物標記。辨識癌症的各種生物標記,將有助生物學家揭開癌症代謝路徑和生化過程的面紗,為研發創新基因療法和評估治療效果的系統帶來重大貢獻。
目前已經有大量的生物資訊方法來辨識這些核酸資料庫的各種癌症生物標記,每一個生物標記表示和某種癌症疾病有顯著關聯。然而使用單一生物標記來預測癌症疾病,其正確率通常不高,難以進行深入分析與後續相關發展。由於癌症的發生牽涉到基因調控網路和代謝路徑等,因此若要使用生物資訊的方法來提高預測癌症的正確率,使用單一生物標記是不夠的,必須使用一組癌症生物標記集合方能奏效。
一片微陣列晶片中就有數以千計以上的基因,經由生物統計方法可以大大縮減候選的生物標記數目,但是所剩數目仍舊不少,需要進一步篩選。由於生物晶片檢測價格不低,且受試者不易尋找,經常導致癌症患者的樣本數不是很大,對應於候選的生物標記數目不少,要從中辨識一組癌症生物標記集合常會導致欠定問題(underdetermined problem),亦即有很多組癌症生物標記集合能夠在數學建模的預測函數上有著相近的預測效能。此外,要從大量的n個候選生物標記中找出一小組m個生物標記,其中m不為已知,並要達到最佳的預測效能,這是一個C(n, m)的組合最佳化問題(combinatorial optimization problem)。
何信瑩所長的智慧計算實驗室致力於發展人工智慧演算法,以演化學習(evolutionary learning)技術發展出辨識一組癌症生物標記集合的雙目標組合最佳化演算法,最佳化雙目標有(1)極大化預測效能,(2)極小化生物標記集合,即最小化m值降低成本,同時考慮欠定問題,希望找出最強健的(robust)一組生物標記集合。已發展的繼承式雙目標組合最佳化基因演算法(inheritable bi-objective combinatorial genetic algorithm, IBCGA)並結合支持向量機(support vector machine)能同時最佳化挑選一小組生物標記集合及決定支持向量機的參數值,達到極大化預測效能。以IBCGA生物資訊方法為基礎的特徵集合辨識演算法應用於蛋白質功能預測和癌症疾病預測等應用已發表多篇期刊論文。
美國癌症基因體圖譜計畫TCGA (The Cancer Genome Atlas) 大規模地蒐集特定癌症病患的臨床記錄和腫瘤組織定序,並公開生物資訊分析分析結果於官方網站供大家瀏覽及下載,而且資料庫一值在擴大中。GEO (Gene Expression Omnibus) 則是歸檔和研究人員提交的高通量基因表現資料的公共資料庫。近年來,從TCGA和GEO等基因表現資料庫進行學術研究和產業應用的開發已受到大眾矚目,也是值得投入更多心血的研究領域。
目前針對研究主題客製化的IBCGA演算法能夠一次辨識一組生物標記集合,從TCGA/GEO等資料庫蒐集表現量資料已成功在microRNA與lncRNA等表現量資料上皆有成果,並發表於Scientific reports和 BMC Genomics期刊,包含了多形性膠質母細胞瘤、肺癌、乳癌、神經膠質母細胞瘤,研究的議題也從癌症的分期到存活時間的預測,如表一。例如在肺癌的主題中,本核心所開發的方法SVR-LUAD在預測肺癌患者的存活時間上,從332 個miRNAs中辨識出有18個miRNAs的生物標記集合,在使用SVR (support vector regression)達到10-fold cross-validation的相關係數0.88和平均絕對誤差(mean absolute error) 0.56 ± 0.03年。對於辨識出來的生物標記,可以依照預測效能對每一個生物標記做名次排序,進一步做Kyoto Encyclopedia of Genes Genomes (KEGG)、Gene Ontology (GO)、Kaplan-Meier 存活曲線等分析。
本核心所提供的研究服務也可結合miRTarBase資料庫,反向知道感興趣的基因會被哪些miRNA所調控。miRTarBase資料庫是蒐集經過實驗驗證的miRNA 標靶基因(miRNA-target interactions, MTIs) 所建置的資料庫。使用者可以在miRTarBase查詢到經不同實驗方法驗證過的受miRNA調控的基因。
表一 、癌症生物標記集合的生物標記數目與預測效能
| Method | Cancer type | Number of miRNAs/lncRNAs | Accuracy /Correlation coefficient | Issue | Reference | |
| SVR-GBM | Glioblastoma multiforme | 24 | 0.76 | survival time | [1] | |
| SVR-LUAD | Lung adenocarcinoma | 18 | 0.88 | survival time | [2] | |
| SVM-BRC | Breast Cancer | 34 | 0.80 | stage prediction | [3] | |
| SVR-NB | Neuroblastoma | 35 | 0.92 | survival time | [4] | |
癌症生物標記集合的研究服務
利用癌症生物標記集合的辨識與分析平台(圖1),本核心提供重要的癌症生物標記集合辨識與分析服務,為癌症治療方式與研究帶來新的機會,將有助於臨床試驗與精準的個人照護醫療。利用癌症生物標記集合的辨識平台,我們致力於發展跨癌症基因生物標記系統檢測平台(圖2),亦即建立一套各種癌症生物標記集合的最小聯集,能夠同時檢測與分析多種癌症的進程與輔助基因治療。
本核心提供以下研究服務:
- 針對各種基因表現資料庫,配合臨床資料的整合分析,辨識關於癌症分期和存活等對應的生物標記集合。
- 對各生物標記的重要性排序、驗證與分析,包含代謝途徑分析與Gene Ontology 標註等。
- 基於IBCGA的智能數學建模與預測能力,可對各種生醫大數據(基因表現量、生物醫學影像、臨床醫學資料庫、腸道微生物菌相分析、EEG腦波、質譜儀頻譜……)提供最佳化的數學建模與預測分析。
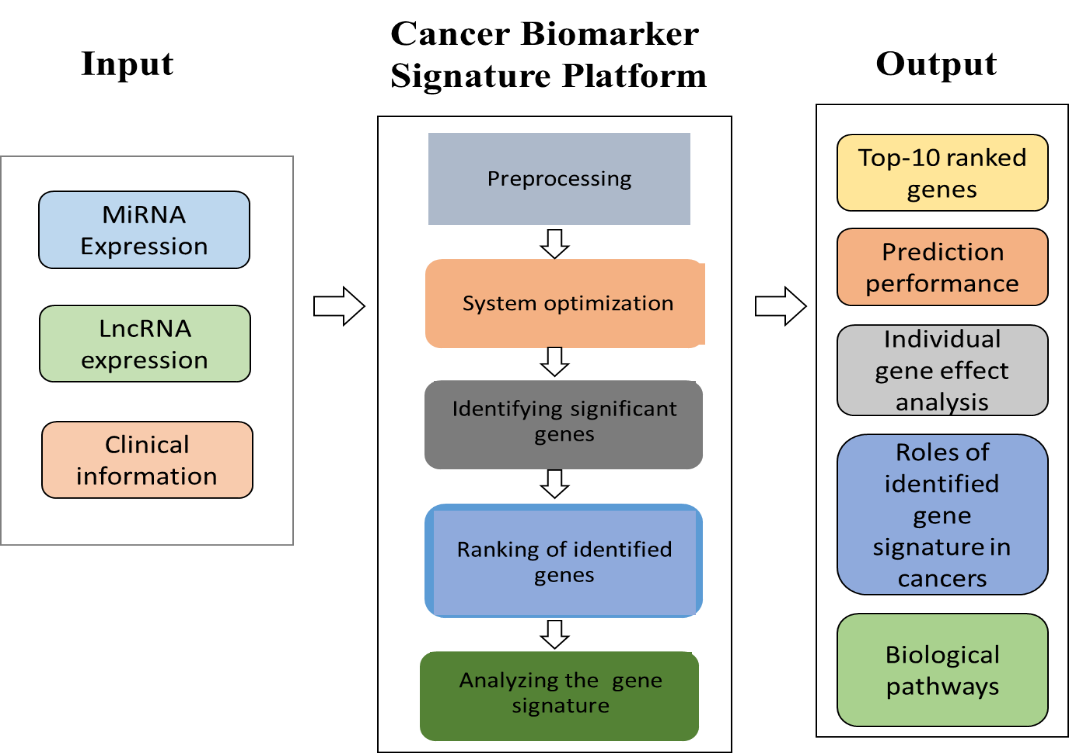
圖1 癌症生物標記集合的辨識與分析平台
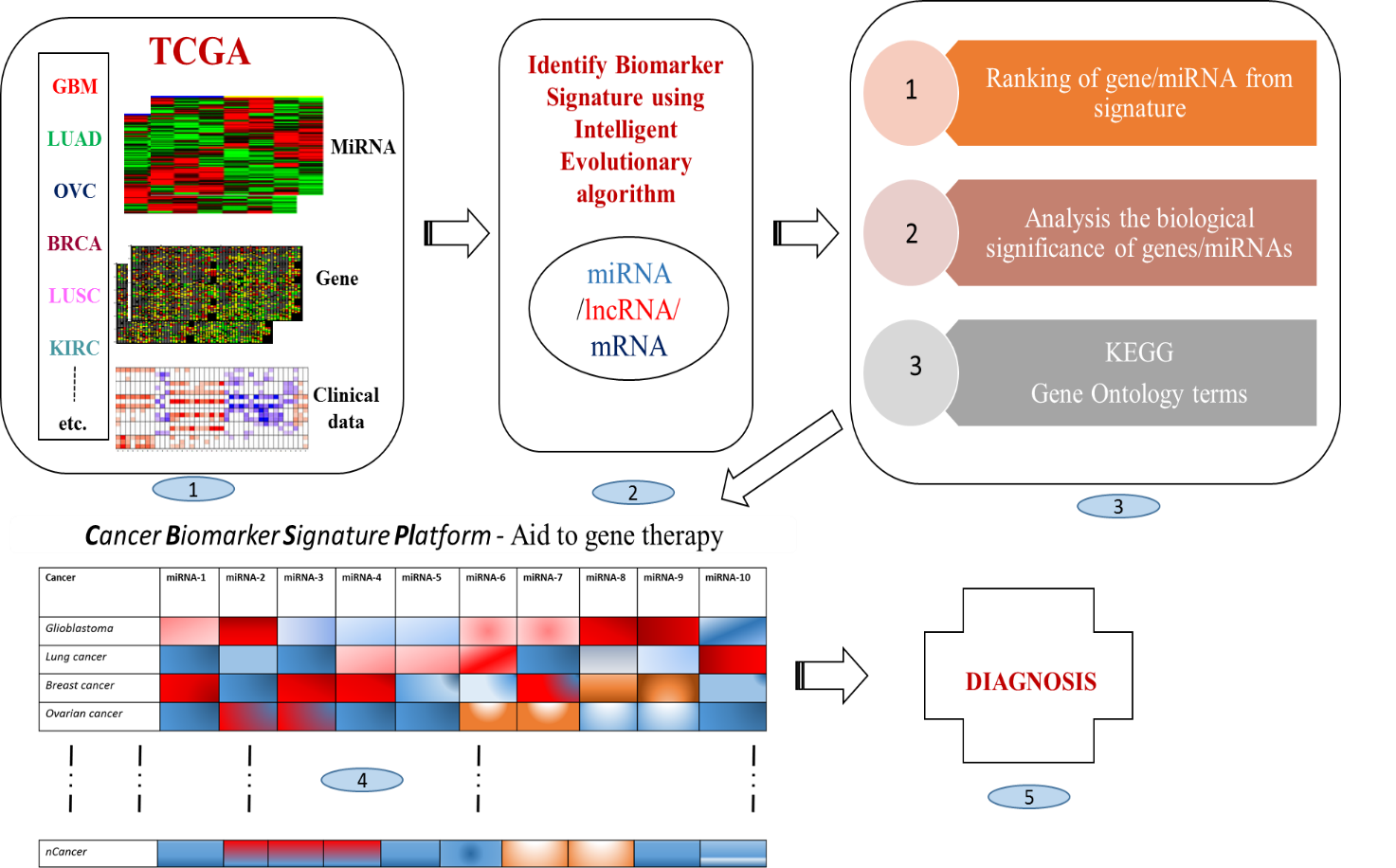
圖2 跨癌症基因生物標記系統檢測平台之綜覽 (1)從TCGA/GEO等資料庫蒐集癌症基因表現量資料 (2)發展一套演化式演算法來辨識各癌症的生物標記集合 (3)系統分析辨識出來的癌症生物標記 (4) 建立一套跨癌症平台來提供系統性建議 (5) 使用跨癌症基因生物標記系統檢測平台來輔助癌症診斷。