
基於Principle-based approach的自然語言處理應用於生醫文獻探勘
Natural Language Processing with Principle-based approach for biomedical text mining
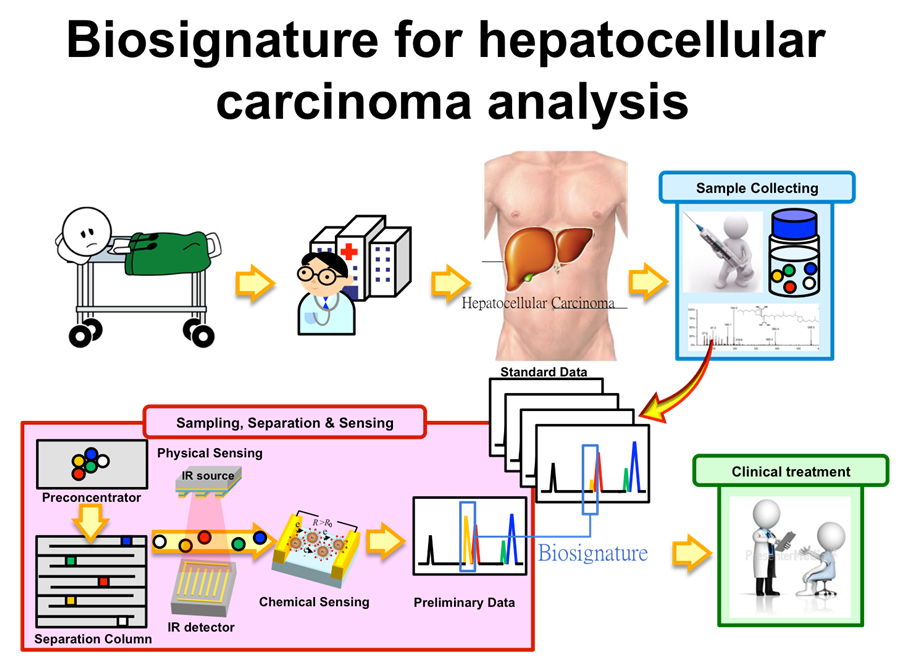
圖:肝細胞癌(Hepatocellular carcinoma, HCC)在臨床上的診斷流程,透過樣本蒐集、萃取及Biosignature分析,作為罹患HCC與否的診斷依據。
自然語言(Natural language)顧名思義即是一般人平常所用的語言。人類的知識有許多都是以自然語言的文字或影音形式儲存。近年來,科技日新月異,生醫方面的文獻數量也隨著倍數成長。其所產生的巨量資料,讓文獻閱讀及收集的困難度也跟著提升。因此,利用自然語言處理(Natural Language Processing, NLP),自動挖掘現今大量已發表於生物醫學文獻中有關生醫物件間之關聯,例如:蛋白質交互作用(Protein-protein interaction, PPI),或是與疾病相關的生物標識(Biomarker/Biosignature),將能輔助生醫專家快速掌握生醫科技之最新成果與整體關聯性,加速相關研究發展,促進生醫科技之應用與創新。
目前自然語言處理的趨勢主要分為法則式模型(rule-based models)與統計模型(statistical models)兩種方法。法則式模型較趨近於人類思考模式,但是例外處理過於瑣碎、複雜,且需要大量人力介入;統計模型強調全自動學習,但學到的大多是一堆數學參數,不易理解及分析,且較不能充分利用細膩的語言知識。有鑑於過去的研究皆缺乏語意上的理解及可讀性。E2轉譯醫學暨生技研發之生物資訊核心設施(Bioinformatics Core Facility for Translational Medicine and Biotechnology Development,簡稱TMBD Bioinformatics Core)中,由許聞廉所長所帶領的團隊,積極研發準則式模型Principle-based approach(PBA),擷取法則式模型與統計模型的優點,避開其缺失。此方法有三個步驟,首先,透過domain expert建構相關領域的本體論/語意地圖(ontology/MAP),針對語料進行語意標注(semantic labeling),標注後所產生的資料稱為pattern,這些pattern是雜亂無章的;接著,經由PBA演算法中的pattern summarization步驟,將patterns加上關鍵樣元的挑選,整合成具有代表性的principles。最後,principle matching則藉由允許substitution, insertion及deletion,強化了傳統的正規表示式(regular expression)過於僵化而無法做到的彈性比對,讓principle matching的自由度更高(flexible)。PBA不僅具有自動擷取生醫文獻中相關資訊的功能,亦能產生可讀性的資料及規則。此研究將有助於自然語言處理未來在生醫文獻探勘上的應用。